Description
Spark is Hadoop MapReduce done in memory
Software Category: devel
For detailed information, visit the Spark website.
Available Versions
To find the available versions and learn how to load them, run:
module spider spark
The output of the command shows the available Spark module versions.
For detailed information about a particular Spark module, including how to load the module, run the module spider command with the module’s full version label. For example:
module spider spark/4.0.0
| Module | Version |
Module Load Command |
|---|
| spark | 4.0.0 |
module load spark/4.0.0
|
Using Spark interactively
There are three ways to use Spark interactively:
- Shell prompt
- Open OnDemand JupyterLab PySpark kernel
- Open OnDemand Desktop
If you need the Web UI you must use the third method (OOD Desktop).
Shell prompt
First submit an ijob.
Scala/PySpark
To start up a Scala or PySpark shell prompt, run spark-shell or pyspark. For example:
$ spark-shell
...
Spark context Web UI available at http://udc-xxxx-xx:4040
Spark context available as 'sc' (master = local[*], app id = local-1633023285536).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.2)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
R
To start an R prompt, you must load R first. Then run sparkR. If the R version is different from 4.1.0, you will see a warning message:
package ‘SparkR’ was built under R version 4.1.0
We recommend loading the closest available version.
Open OnDemand JupyterLab PySpark kernel
Starting from version 4.0.0, the PySpark kernel is available through the JupyterLab Interactive App on Open OnDemand.
The PySpark 3.4 Interactive App will be removed in the near future.
Open OnDemand Desktop
Spark provides a user interface (UI) for you to monitor your Spark job. If you intend to use the Web UI, you must request a Desktop session through Open OnDemand.
The URL is displayed upon launching Spark and is of the form http://udc-xxxx-xx:4040 where udc-xxxx-xx is the hostname of the compute node. You can either right-click on the link and select “Open Link,” or enter localhost:4040 in the browser.
Jupyter notebook/lab
You can redirect pyspark to open a Jupyter notebook/lab as follows. First load the modules:
module load spark/4.0.0 jupyterlab
Set two environment variables:
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS=lab
If you’d prefer a notebook session, replace lab with notebook.
Navigate to your working directory and run:
pyspark
This will start up Jupyter inside a browser automatically. Select the Python 3 kernel, not PySpark.
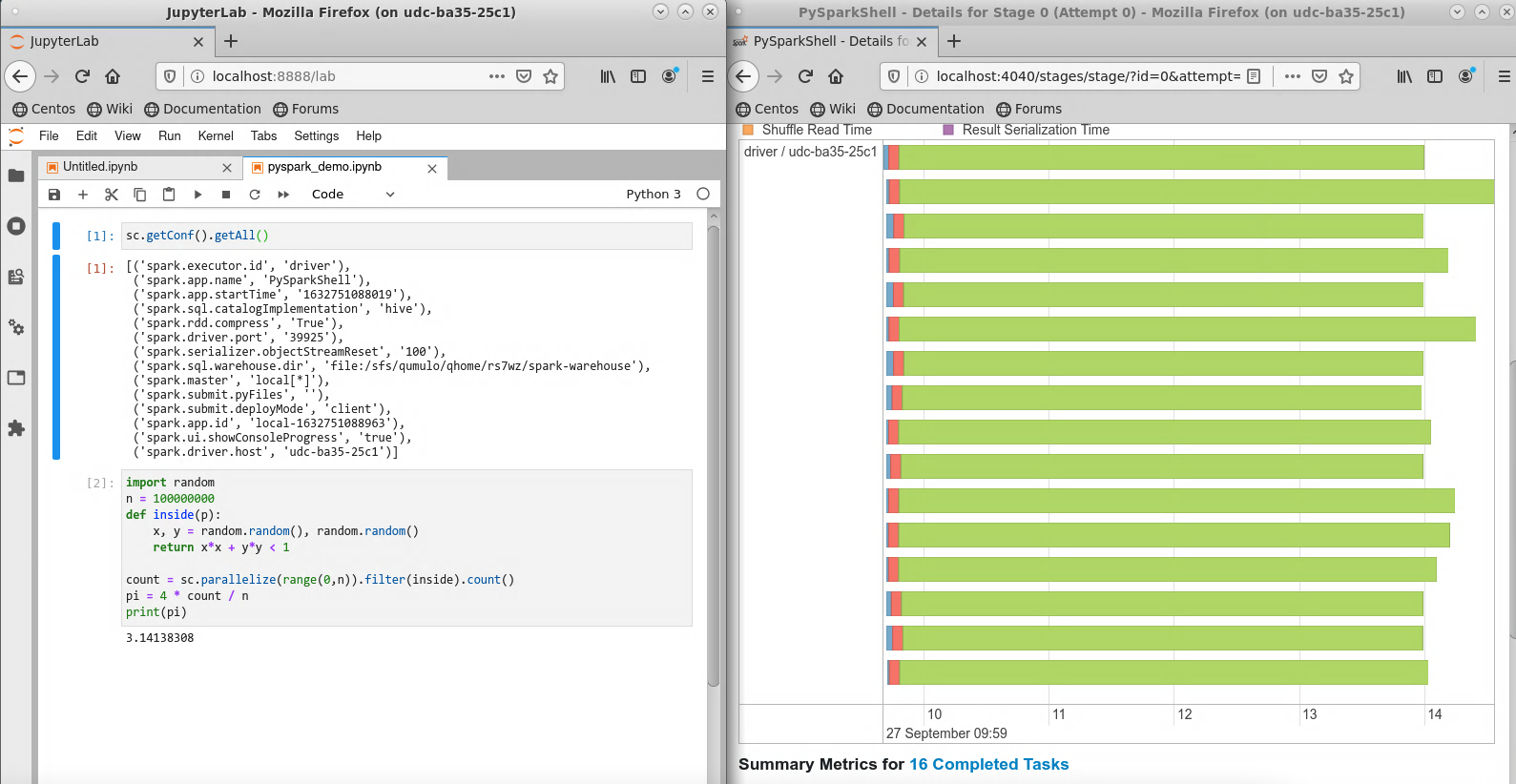
The example below estimates the value of pi, with the JupyterLab window on the left and the Spark Web UI event timeline on the right. Note that the SparkContext object sc is initialized automatically.
Slurm Script Templates for Batch Jobs
Local mode on a single node
#!/bin/bash
#SBATCH -p standard # partition
#SBATCH -A myaccount # your allocation
#SBATCH -N 1 # number of nodes
#SBATCH -c 10 # number of cores per node
#SBATCH -t 10:00:00 # time
module purge
module load spark
spark-submit script.py
You must initialize SparkContext explicitly in your script, e.g.:
from pyspark import SparkContext
sc = SparkContext("local[*]")
The Spark log is written to slurm-<JOB_ID>.out. After the job is finished, use the seff <JOB_ID> command to verify that the cores are used effectively:
$ seff 1232109
...
Cores per node: 10
CPU Utilized: 01:17:16
CPU Efficiency: 82.20% of 01:34:00 core-walltime
...
If the CPU efficiency is much lower, please consider using fewer cores for your future jobs.
Standalone cluster mode using multiple nodes
We gratefully acknowledge Advanced Research Computing at the University of Michigan for the spark-start script. The following is implemented for module versions 4.0.0 and above.
Before requesting multiple nodes, please make sure that your job can use a full standard node effectively. When you request N nodes in the standalone cluster mode, one node is set aside as the master node and the remaining N-1 nodes are worker nodes. Thus, running on 2 nodes will have the same effect as running on 1 node.
#!/bin/bash
#SBATCH -A myallocation # replace with your actual allocation
#SBATCH -p parallel # partition
#SBATCH -N 3 # number of nodes
#SBATCH -c 96 # cores per node
#SBATCH --mem=100G # memory per node
#SBATCH -t 10:00:00 # time
SPARK_VERSION=4.0.0
#---------------------------
# do not modify this section
TEC=$(((SLURM_NNODES-1)*SLURM_CPUS_PER_TASK))
EM=$((SLURM_MEM_PER_NODE/1024))
module purge
module load spark/$SPARK_VERSION
spark-start
source ${HOME}/.spark-local/${SLURM_JOB_ID}/spark/conf/spark-env.sh
#---------------------------
spark-submit --master $SPARK_MASTER_URL --executor-memory ${EM}G --total-executor-cores $TEC pi.py
It is recommended that all cores (96 per parallel node) be requested. Advanced users may make a copy of $SPARK_HOME/bin/spark-start and customize it before submission; specify the path to your local copy in the Slurm script.
Temporary files are created in ~/.spark-local/<JOB_ID> and may be safely removed after the job completes.