Description
Julia is a high-level programming language designed for high-performance numerical analysis and computational science. Distinctive aspects of Julia’s design include a type system with parametric polymorphism and types in a fully dynamic programming language and multiple dispatch as its core programming paradigm. It allows concurrent, parallel and distributed computing, and direct calling of C and Fortran libraries without glue code. A just-in-time compiler that is referred to as “just-ahead-of-time” in the Julia community is used. [Ref: Wikipedia](https://en.wikipedia.org/wiki/
Software Category: lang
For detailed information, visit the julia
website.
Available Versions
To find the available versions and learn how to load them, run:
module spider julia
The output of the command shows the available julia
module versions.
For detailed information about a particular julia
module, including how to load the module, run the module spider command with the module’s full version label. For example:
module spider julia/1.9.2
| Module | Version |
Module Load Command |
|---|
| julia | 1.9.2 |
module load julia/1.9.2
|
Installing Julia Packages
Julia wants to update any existing packages whenever a user tries to add a package. Of course, the basic packages were installed in a system directory that is not writable by the users.
One work-around is to force Julia to use your local directory the first time that you add a package. For example, from the Linux command line set the shell variable,
export JULIA_DEPOT_PATH="~/.julia"
Then when you add a package from within Julia, it will be added to the .julia folder in your home directory, e.g.
After that first time, it should aways default to /home/$USER/.julia .
The following link is a useful reference for loadin Julia pacakges.
Loading Packages
The follwoing code snippet shows the steps used on my UVA HPC account to install and verify the SharedArrays package.
udc-ba34-36-gahlmann$module load julia
udc-ba34-36-gahlmann$julia
_
_ _ _(_)_ | Documentation: https://docs.julialang.org
(_) | (_) (_) |
_ _ _| |_ __ _ | Type "?" for help, "]?" for Pkg help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 1.6.0 (2021-03-24)
_/ |\__'_|_|_|\__'_| | Official https://julialang.org/ release
|__/ |
julia> using Pkg
(v1.6) pkg> status
Status `/sfs/qumulo/qhome/teh1m/.julia/environments/v1.6/Project.toml`
[91a5bcdd] Plots v1.19.4
[8ba89e20] Distributed
[de0858da] Printf
julia>
help?> sdata
search: isdirpath isdispatchtuple StridedMatrix StridedVecOrMat searchsortedlast
Couldn't find sdata
Perhaps you meant stat, sort, sort!, sqrt, ispath, lstat, edit, Meta or atan
No documentation found.
Binding sdata does not exist.
(v1.6) pkg> add SharedArrays
Updating registry at `~/.julia/registries/General`
Resolving package versions...
Updating `/sfs/qumulo/qhome/teh1m/.julia/environments/v1.6/Project.toml`
[1a1011a3] + SharedArrays
No Changes to `/sfs/qumulo/qhome/teh1m/.julia/environments/v1.6/Manifest.toml`
(v1.6) pkg> status
Status `/sfs/qumulo/qhome/teh1m/.julia/environments/v1.6/Project.toml`
[91a5bcdd] Plots v1.19.4
[8ba89e20] Distributed
[de0858da] Printf
[1a1011a3] SharedArrays
julia> using SharedArrays
help?> sdata
search: sdata isdirpath isdispatchtuple SharedMatrix StridedMatrix
sdata(S::SharedArray)
Returns the actual Array object backing S.
julia>
You can work with Julia on the UVA HPC frontend nodes; we recommend FastX for this application.
Interactive Sessions through the Open OnDemand Web Portal
Starting an Interactive Session
To launch an instance of julia
through a notebook interface, you will begin by connecting to our Open OnDemand portal. You need to specify required resources, e.g. node partition, time, your UVA HPC allocation, etc.. If you are new to HPC, you may want to read the Getting Started Guide to learn more about the partitions.
- Open a web browser and go to URL: https://ood.hpc.virginia.edu.
- Use your Netbadge credentials to log in. This will open the Open OnDemand web portal.
- On the top banner of the Open OnDemand dashboard, click on
Interactive Apps.
- In the drop-down box, click on
JupyterLab.
- After connecting to
JupyterLab`` through Open OnDemand, a form will appear where you can fill in the resources for JupyterLab`.
- When done filling in the resources, click on the blue
Launch button at the bottom of the form. Do not click the button multiple times.
- It may take a few minutes for the system to gather the resources for your instance of
JupyterLab. When the resources are ready a Connect to JupyterLab button will appear. Click on the button to start JupyterLab.
Using JupyterLab
When JupyterLab opens in your web browser, it will appear with a selection of notebook kernels to choose from, as shown below.
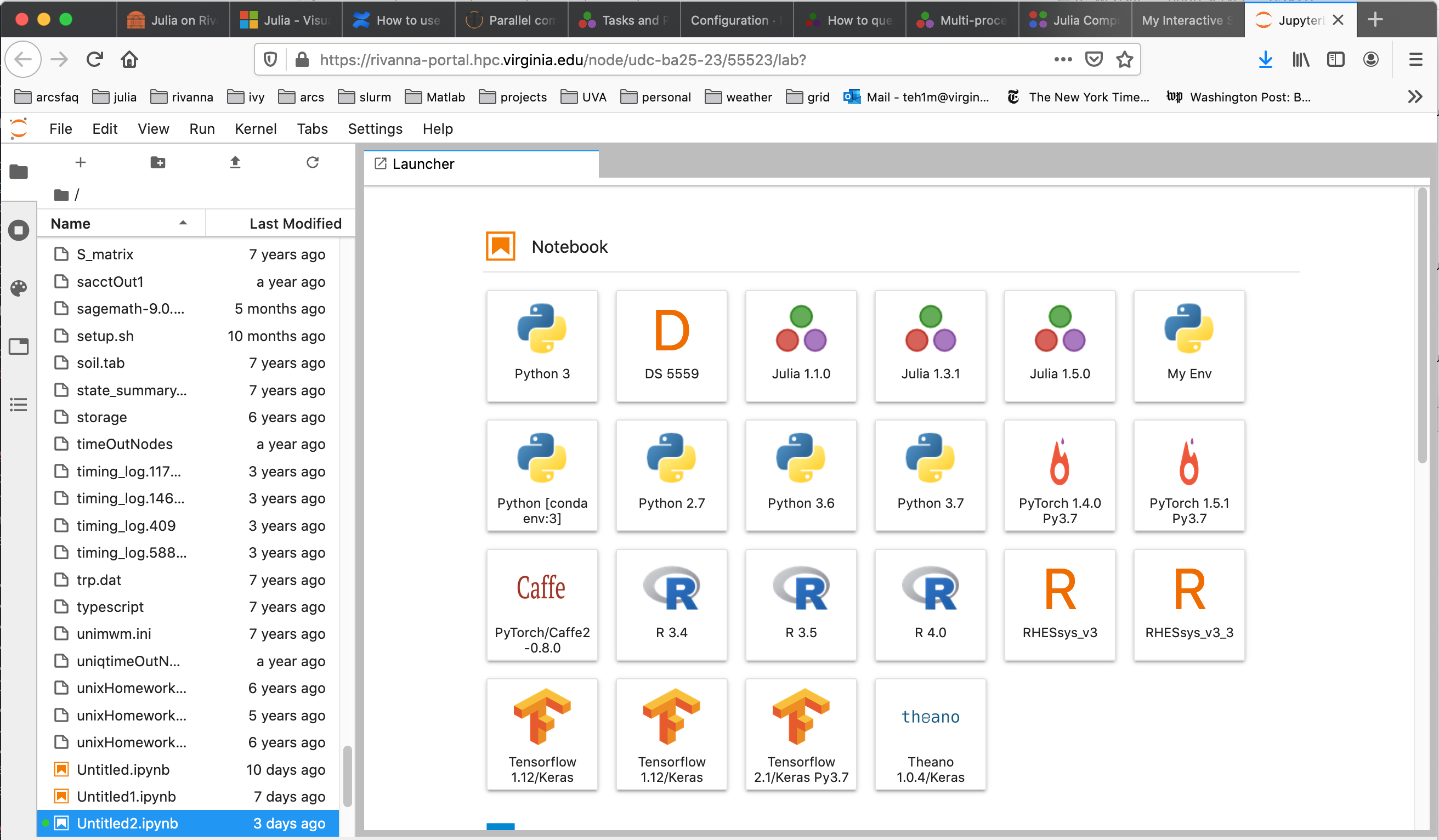
If you double-click on one of the Julia kernels, an IPython notebook will open connected to Julia, ready for interactive commands.
Closing the Interactive Session
When you are done, quit the JupyterLab application. The interactive session will be closed and the allocated resources will be released. If you leave the session open, your allocation will continue to be charged until the specified time limit is reached.
Running a Julia Batch Jobs on the HPC System
The UVA HPC system uses the Slurm resource manager to schedule and run jobs on the cluster compute nodes. The following are example Slurm scripts for submitting different types of Julia batch jobs to the cluster.
Submitting a batch job using a single core of a compute node.
Once your program is debugged, we recommend running in batch mode when possible. This runs the job in the background on a compute node. Write a Slurm script similar to the following:
#!/bin/bash
# This slurm script file runs
# a single-core Julia job (on one compute node)
#SBATCH -p standard
#SBATCH -A hpc_build
#SBATCH --time=00:10:00
#SBATCH --mail-type=end
#SBATCH --mail-user=teh1m@virginia.edu
#SBATCH --job-name=SingleTest
#SBATCH --output=SingleTest_%A.out
#SBATCH --error=SingleTest_%A.err
#SBATCH --ntasks=1
# Load Julia environment
module load julia/1.5.0
julia hello.jl
The simple example code hello.jl is shown below.
msg="hello world"
println(msg)
Submitting a batch job using multiple cores on a compute node
The Distributed package can be used to run Julia code across multiple cores of a compute node. The Slurm script in this case would look like the following:
#!/bin/bash
# This slurm script file runs
# a single-core Julia job (on one compute node)
#SBATCH -p standard
#SBATCH -A hpc_build
#SBATCH --time=00:10:00
#SBATCH --mail-type=end
#SBATCH --mail-user=teh1m@virginia.edu
#SBATCH --job-name=SingleTest
#SBATCH --output=SingleTest_%A.out
#SBATCH --error=SingleTest_%A.err
#SBATCH --ntasks=1
# Load Julia environment
module load julia/1.5.0
julia hello.jl
The Julia code in this case is,
using Distributed
# launch worker processes
num_cores = parse(Int, ENV["SLURM_CPUS_PER_TASK"])
addprocs(num_cores)
println("Number of cores: ", nprocs())
println("Number of workers: ", nworkers())
# each worker gets its id, process id and hostname
for i in workers()
id, pid, host = fetch(@spawnat i (myid(), getpid(), gethostname()))
println(id, " " , pid, " ", host)
end
# remove the workers
for i in workers()
rmprocs(i)
end
and the output is,
Number of cores: 9
Number of workers: 8
2 11643 udc-ba26-19
3 11644 udc-ba26-19
4 11645 udc-ba26-19
5 11646 udc-ba26-19
6 11649 udc-ba26-19
7 11650 udc-ba26-19
8 11651 udc-ba26-19
9 11652 udc-ba26-19
Documentation on distributed computing with Julia can be accessed at the URL
Julia Jobs using Slurm Job Arrays
Slurm has a mechanism for launching multiple independent jobs with one
job script using the --array directive.
Array of Multiple Single-Core Julia Jobs
The following slurm script shows how to run 5 single core Julia jobs using
Slurm job arrays.
#!/bin/bash
# This slurm script file runs
# a single-core Julia job (on one compute node)
#SBATCH -p standard
#SBATCH -A hpc_build
#SBATCH --time=00:10:00
#SBATCH --mail-type=end
#SBATCH --mail-user=teh1m@virginia.edu
#SBATCH --job-name=SingleTest
#SBATCH --output=SingleTest_%A.out
#SBATCH --error=SingleTest_%A.err
#SBATCH --ntasks=1
# Load Julia environment
module load julia/1.5.0
julia hello.jl
The jobArray.jl code can use the SLURM_ARRAY_TASK_ID shell variable assigned by
Slurm for indexing input file.
using Distributed
num_replication = Base.parse(Int, ENV["SLURM_ARRAY_TASK_ID"])
@everywhere println("Job array task id: ", num_replication, " on host $(gethostname())")
The Slurm script will produce 5 separate output files, each of the form
Job array task id: 4 on host udc-ba25-33c0
Parallel Julia on Multiple Compute Nodes
To run Julia parallel jobs that require more cores than are available on one compute node (e.g. > 40), please use the system MPI libraries. You cannot use the aforementioned Distributed package since it requires SSH permission into compute nodes.
#!/bin/bash
# This script uses Julia's MPI package that
# uses the Intel MPI library on Rivanna. See the URL
# https://juliaparallel.github.io/MPI.jl/stable/configuration/
#SBATCH -p parallel
#SBATCH -A hpc_build
#SBATCH --time=00:10:00
#SBATCH --mail-type=end
#SBATCH --mail-user=teh1m@virginia.edu
#SBATCH --job-name=parallelTest1
#SBATCH --output=parallelTest1_%A.out
#SBATCH --error=parallelTest1_%A.err
#SBATCH --nodes=8 #Number of nodes
#SBATCH --ntasks-per-node=1 #Number of cores per node
# Load Julia environment
module load julia
module load intel
srun julia helloParallel.jl
This involves importing the Julia MPI module:
import MPI
MPI.Init()
comm = MPI.COMM_WORLD
my_rank = MPI.Comm_rank(comm)
comm_size = MPI.Comm_size(comm)
println("Hello! I am ", my_rank, " of ", comm_size, " on ",gethostname())
MPI.Finalize()
To take advantage of the fast network interfaces between compute node, use the
system-provided MPI implementations. See the documentation on using a system-provided MPI.
The output of this program should look like,
Hello! I am 6 of 8 on udc-ba34-16c4
Hello! I am 1 of 8 on udc-ba34-10c9
Hello! I am 3 of 8 on udc-ba34-16c1
Hello! I am 5 of 8 on udc-ba34-16c3
Hello! I am 7 of 8 on udc-ba34-16c5
Hello! I am 2 of 8 on udc-ba34-16c0
Hello! I am 4 of 8 on udc-ba34-16c2
Hello! I am 0 of 8 on udc-ba34-10c8
Utilizing GPUs with Julia
General guidelines on requesting GPUs on UVA HPC
The following slurm script is for submitting a Julia job that uses 1 GPU. For each GPU requested, the script requests one cpu (ntasks-per-node). The article An Introduction to GPU Programming in Julia provides more details to get started.
#!/bin/bash
# This slurm script is an example of submitting a Julia
# code to a gpu
#SBATCH --partition=gpu
#SBATCH --gres=gpu:1
#SBATCH -A hpc_build
#SBATCH --time=1:00:00
#SBATCH --output=run_gpu_%A.out
#SBATCH --error=run_gpu_%A.err
#SBATCH --mail-type=end
#SBATCH --mail-user=teh1m@virginia.edu
#SBATCH --ntasks-per-node=1 # allocate one cpu for each gpu
##SBATCH --mem=60000
echo 'slurm allocates gpus ' $CUDA_VISIBLE_DEVICES
module purge
module load julia/1.5.0 cuda/10.2.89
julia gpuTest1.jl
The Julia code is
using Flux, CuArrays
z = CuArrays.cu([1, 2, 3])
println(2 * z)
m = Dense(10,5) |> gpu
x = rand(10) |> gpu
println(m(x))
and the output is
slurm allocates gpus 4
[2, 4, 6]
Float32[0.6239201, -0.36249122, -1.1242702, -0.9278027, 0.004131808]