

Afton is the University of Virginia's newest High-Performance Computing system. The Afton supercomputer is comprised of 300 compute node each with 96 compute cores based on the AMD EPYC 9454 architecture for a total of 28,800 cores. The increase in core count is augmented by a significant increase in memory per node compared to Rivanna. Each Afton node boasts a minimum of 750 Gigabytes of memory, with some supporting up to 1.5 Terabytes of RAM memory. The large amount of memory per node allows researchers to efficiently work with the ever-expanding datasets we are seeing across diverse research disciplines. The Afton and Rivanna systems provide access to 55 nodes with NVIDIA general purpose GPU accelerators (RTX2080, RTX3090, A6000, V100, A40, and A100), including an NVIDIA BasePOD. The Afton and Rivanna platforms share storage systems of over 8 Petabytes and a stack of pre-installed software packages available for computational research across many disciplines.
Rivanna is one of the University of Virginia's High-Performance Computing (HPC) systems. After hardware upgrades and expansions in 2019, the Rivanna supercomputer currently has 603 nodes with over 20,476 compute cores. The Rivanna and Afton systems provide access to 55 nodes with NVIDIA general purpose GPU accelerators (RTX2080, RTX3090, A6000, V100, A40, and A100), including an NVIDIA BasePOD. Both platforms share storage systems of over 8 Petabytes and a stack of pre-installed software packages available for computational research across many disciplines.
Facilities Statement - Are you submitting a grant proposal and need standard information about UVA research computing environments?
Get it here.
The sections below contain important information for new and existing Rivanna and Afton users. Please read each carefully.
New users are invited to attend one of our free orientation sessions ("Introduction to HPC") held throughout the year.
Get Started
Logging In
Log in through a Web browser or a command-line tool.
File Transfer
Moving files between Rivanna/Afton and other systems.
Software
See a listing of available software.
Storage
Options for free short-term and leased long-term storage
Running Jobs in Slurm
Submitting jobs to Rivanna/Afton through the Slurm resource manager
Job Queues
Determine the best queue (or “partition”) for running your jobs.
Usage Policies
Understand the terms and conditions for using Rivanna/Afton.
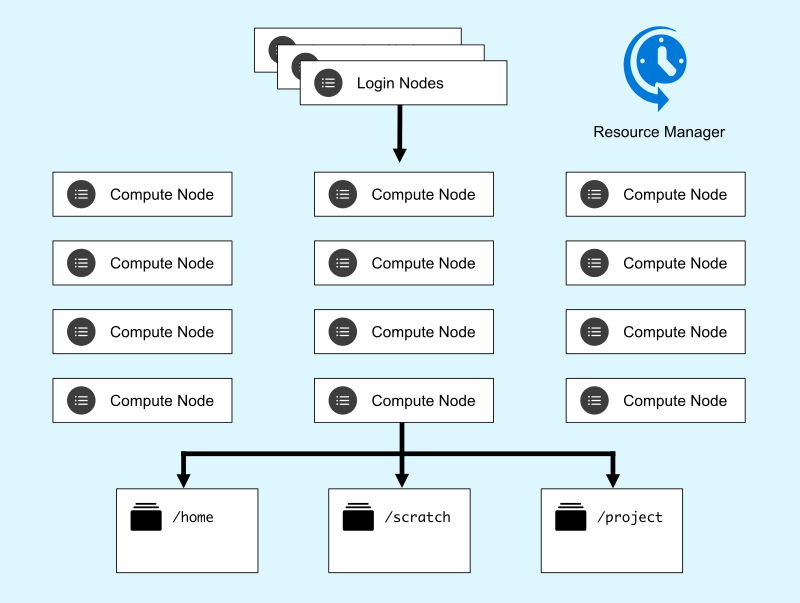
Overview
A high performance computing cluster is typically made up of at least four service layers:
- Login nodes - Where you log in, interact with data and code, and submit jobs.
- Compute nodes - Where production jobs are run. On Rivanna and Afton these nodes are heterogeneous; some have more memory, some have GPU devices, and so forth. Partitions are homogeneous so you can select specialty hardware by your partition request, sometimes along with a resource request (gres).
- Storage - Where files are stored, accessible by all nodes in the cluster.
- Resource Manager - A software system that accepts job requests, schedules the jobs on a node or set of nodes, then manages their execution.
Click on elements of the image to learn more:
System Details
Hardware Configuration
| System |
Cores/Node |
Memory/Node |
Specialty Hardware |
GPU memory/Device |
GPU devices/Node |
# of Nodes |
SU/CPU-hr |
SU/GB-hr |
SU/GPU-hr |
| Rivanna |
40 |
375GB |
- |
- |
- |
182 |
0.177 |
0.0143 |
0 |
| Afton |
96 |
750GB |
- |
- |
- |
280 |
0.464 |
0.0284 |
0 |
| Rivanna |
40 |
750GB |
- |
- |
- |
40 |
0.13 |
0.009 |
0 |
| Afton |
96 |
1464GB |
- |
- |
- |
20 |
0.418 |
0.0244 |
0 |
| Afton |
128 |
976GB |
GPU: A100 |
40GB |
8 |
2 |
0.311 |
0.0292 |
46.381 |
| Afton |
128 |
1953GB |
GPU: A100 |
80GB |
8 |
18 |
0.403 |
0.043 |
50.89 |
| Afton |
96 |
1464GB |
GPU: A40 |
48GB |
8 |
12 |
0.34 |
0.02 |
18.669 |
| Afton |
48 |
250GB |
GPU: A6000 |
48GB |
8 |
14 |
0.383 |
0.062 |
14.273 |
| Afton |
40 |
374GB |
GPU: RTX2080Ti |
11GB |
10 |
2 |
0.388 |
0.041 |
7.757 |
| Afton |
32 |
125GB |
GPU: RTX3090 |
24GB |
4 |
4 |
0.303 |
0.076 |
11.323 |
| Afton |
36 |
375GB |
GPU: V100 |
32GB |
4 |
2 |
0.058 |
0.005 |
2.096 |
Facilities Statement - Are you submitting a grant proposal and need standard information about UVA research computing environments?
Get it here.
Job Queues
Rivanna and Afton are managed resources; users must submit jobs to queues controlled by a resource manager, also known as a queueing system. The manager in use on Rivanna and Afton is Slurm. Slurm refers to queues as partitions because they divide the machine into sets of resources. There is no default partition and each job must request a specific partition. Partitions and access policies are subject to change, but the following table shows the current structure. Note that memory may be requested per core or for the overall job. If the total memory required for the job is greater than the number of cores requested multiplied by the maximum memory per core, the job will be charged for the additional cores whether they are used or not. In addition, jobs running on more than one core may still require a request of total memory rather than memory per core, since memory per core is enforced by the system but some multicore software packages (ANSYS, for example) may exceed that for a short time even though they never exceed cores x memory/core.
| Partition |
Purpose |
Max time / job |
Max nodes / job |
Max cores / job |
Max cores / node |
Default memory / core |
Max memory / node / job |
| standard |
For jobs on a single compute node |
7 days |
1 |
96 |
96 |
9GB |
1462GB |
| parallel |
For large parallel jobs on up to 64 nodes |
3 days |
64 |
6000 |
96 |
8GB |
750GB |
| gpu |
For jobs using general purpose graphical processing units |
3 days |
4 |
32GPU |
128 |
6GB |
1953GB |
| gpu-mig |
For smaller GPU jobs |
3 days |
1 |
2 |
14 MIGs/user |
4000MB |
30000MB |
| interactive |
For quick interactive sessions |
12 hours |
2 |
24/2GPU |
96 |
6GB |
216GB |
standard maximum aggregate CPU cores allowed for a single user’s running jobs is 1000.parallel requires at least 2 nodes and 4 CPU cores.- Slurm’s default memory unit is in MB. Different units may be specified, e.g.
--mem=100G, where 1G = 1024M.
- The
gpu partition is dedicated to jobs that can utilize a general purpose graphics processing unit (GPGPU). In Slurm scripts you must request at least one GPU device through --gres=gpu. Jobs that do not utilize any GPUs are not allowed in this partition.
interactive maximum aggregate CPU cores (GPUs) is 24 (2) for a single user.- The NVIDIA DGX BasePOD offers high-performance GPUs that bring new AI and ML functionality to support parallel GPU computing and large deep-learning models.
Usage Policies
Research computing resources at the University of Virginia are for use by faculty, staff, and students of the University and their collaborators in academic research projects. Personal use is not permitted. Users must comply with all University policies for access and security to University resources. The HPC system has additional usage policies to ensure that this shared environment is managed fairly to all users. UVA’s Research Computing (RC) group reserves the right to enact policy changes at any time without prior notice.
Login Nodes
Exceeding the limits on the login nodes (frontend) will result in the user’s process(es) being killed. Repeated violations will result in a warning; users who ignore warnings risk losing access privileges.
Scratch Directory
UVA HPC's scratch file system has a limit of 10TB per user. This policy is in place to guarantee the stability and performance of the scratch file system. Scratch is intended as a temporary work directory. It is not backed up and files that have not been accessed for more than 90 days are marked for deletion. Users are encouraged to back up their important data. Home directories and leased storage are not subject to this policy.
Software Licenses
Excessive consumption of licenses for commercial software, either in time or number, if determined by system and/or RC staff to be interfering with other users’ fair use of the software, will subject the violator’s processes or jobs to termination without warning. Staff will attempt to issue a warning before terminating processes or jobs but inadequate response from the violator will not be grounds for permitting the processes/jobs to continue.
Inappropriate Usage
Any violation of the University’s security policies, or any behavior that is considered criminal in nature or a legal threat to the University, will result in the immediate termination of access privileges without warning.
Users are required to comply with all applicable University policies governing acceptable use of information technology resources. This includes restrictions on downloading or using prohibited applications such as DeepSeek AI, TikTok, WeChat, and CapCut on RC resources.
In addition, users are responsible for safeguarding research records in accordance with RES-002: Ownership, Retention, Safeguarding, Management, and Transfer of Research Records and should adhere to the University’s Generative AI Use Guidelines. This includes maintaining research records on University-owned and/or University-managed devices, systems, or services. The University recommends the use of appropriately contracted and licensed Gen AI tools to prevent the inadvertent exposure of internal use or sensitive data.